
Kadel Labs Pvt Ltd
 Madri/Udaipur
Madri/Udaipur
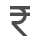 10L-13L/Year
10L-13L/Year
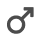 Male/Female
Male/Female
Senior Software Engineer- Databricks Engineer (Job ID ZR_176_JOB) Kadel Labs is a first-of-its-kind Venture Studio in India. It is a global software technology system incubator with synergetic blend of IT Services and SaaS products under its portfolio. Since 2017, KL has grown organically (180+ employees and expanding) and served 200+ Customers. At the core, KL is a people's company. We serve clients by practicing an employee-centric culture and creating an environment where ideas, creativity, free-flowing communication and innovation is encouraged to create better products and services. Role: SSE-Databricks Engineer Experience: 3-5 years Location: Udaipur/Kolkata Job Description: Databricks engineer who has strong experience in Cloud technologies and infra set up. Able to create data warehousing models. Responsibilities: • Cloud technologies (Azure data services Azure ADLS SHIR ADF Integration with Active directory masking and encryption Governance activities Lineage Catalogue classifications. • Infrastructure setup in Azure) Experienced with multiple data-ingestion methods for loading data to Databricks: • ADF python Copy Into for large volume of data as well as incremental data handling Data lake and Data Warehouse Design and optimization Data Analysis CDC • Must Have Technical understanding of digital customer experience layers Been Leading and built at least 1-2 Projects on Azure cloud with Databricks • Experience with CDC and metadata driven based processing. • Have build DWH models Must Have Agile methodology Nice to understand Agile and devops methodology for cloud deployment. • Nice to Have Team Skills Working experience to work with Indian banking industry. • Work with cross functional teams including QA Platform Delivery and DevOps. Not afraid of refactoring existing system and guiding the team about same. • Must Have Delivery Management Able to plan and deliver project deliverable on time with quality. Requirements/Skills: • 3-5 years of demonstrable experience in enterprise level data platforms involving implementation of end-to-end data pipelines • Hands-on experience in using Databricks • Hands-on experience with at least one of the leading public cloud data platforms (Amazon Web Services, Azure or Google Cloud) • Experience with column-oriented database technologies (e.g., Big Query, Redshift, Vertica), NoSQL database technologies (e.g., DynamoDB, BigTable, Cosmos DB, etc.) and traditional database systems (e.g., SQL Server, Oracle, MySQL) • Experience in architecting data pipelines and solutions for both streaming and batch integrations using tools/frameworks like Glue ETL, Lambda, Google Cloud DataFlow, Azure Data Factory, Spark, Spark Streaming, etc. • Certification on Databricks Data Engineer. • Must have Delta Lake Concepts, Delta Live tables and Streaming Data. • Understanding on CICD and repo. • Experience in Apache Spark Configuration and optimization techniques Education and Experience: BTech or relevant educational field required Visit us: https://kadellabs.com/ https://in.linkedin.com/company/kadel-labs
Graduation
5 days per week
3-5 Years
1
Job Dhundo Aasani Se

Download the app now



 Category -
Category -
 City -
City -
 Area -
Area -
Wanna join JobsKart team ?
Mail us on info@jobskart.co







Share